GPUSort versus qsort()on theCPU
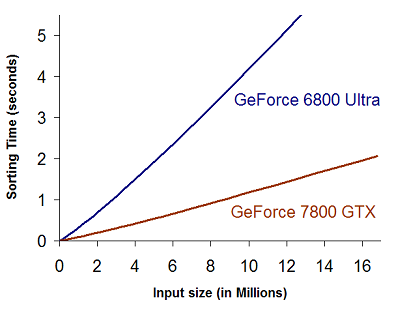
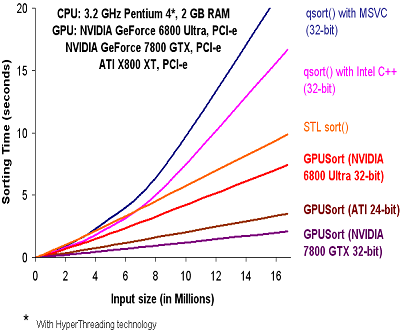
We have observed considerable speedups with GPUSort over qsort() running on the CPU, even for high-end machines. The following graphs show the timings for two test systems. Note that in both cases, GPUSort performs considerably faster. The qsort routine in the Intel C++ compiler is optimized using hyper-threading and SSE instructions.
 |
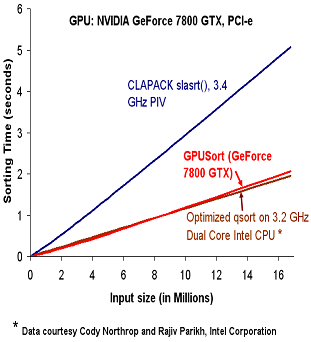 |
The implementation can handle both 16 and 32-bit floats. Our results on the ATI X800 XT and NVIDIA GeForce 6800 GPUs indicate better performance in comparison to the qsort and stlsort routines on a 3.4 GHz Pentium IV PC. Our timings for GPU-based sorting include the data upload and readback time from the GPU. Our algorithm performs much better than CLAPACK on a 3.4 GHz Pentium IV PC with a NVIDIA 7800GTX GPU. The performance on 32-bit floating point data is comparable to a hand optimized implementation on 3.2 GHz Intel dual core processors.
On pointer data (example 3 of the distribution), we have observed a similar comparable performance against the same hand-optimized implementation on a 3.2 GHz Intel dual core processor (CPU data courtesy: Cody Northrop, Intel Corporation), and an order of magnitude improvement over other sorting implementations on high end single core processors. For instance, our algorithm takes nearly 2s to sort 8 million database records on a 7800 GTX GPU whereas the hand-optimized algorithm takes 1.5s on a 3.2 GHz dual core processor.
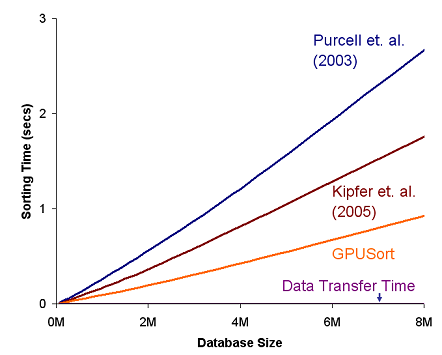
Comparison of GPUSort with previous approaches for sorting on the GPU
The following graph compares the performance of GPUSort with two prior GPU-based sorting algorithms (Purcell et al. 2003, Kipfer et al. 2005) on a NVIDIA 7800 GTX GPU. These algorithms also implement Bitonic Sort on the GPU for 16/32-bit floats using the programmable pipeline of GPUs. However, as shown in the graphs below, GPUSort performs at least 2 times better than these algorithms for 32-bit floats as we effectively utilize the special purpose texture mapping functionality of the GPUs.